Not a summarization trick — a fix to progressive information loss
The Prologue
From my very first interaction with ChatGPT in late 2023, I asked one simple question:
“How do I optimize you?”
That became my approach to every LLM.
By June 2024, something broke in a useful way.
Three different models started showing clear opinions—the mirrored traits of their training data were obvious, but also usable.
When I got more interested in their cognitive behavior, I dug deeper. That’s how Team LLM and ‘AI Anthropology’ began: treating them not just as tools, but as hilariously clever child-collaborators.

Today, Chat, Claude, Gemini, Grok, Qwen, Kimi, DeepSeek, and Perplexity have not only broken public records (Gemini – 51 page Deloitte Benchmark, Claude Sonnet -14,986 words OS One-shot) but are conditioned to my cascade of prompts that outside models cower to.
Even after I wiped GPT‑5’s memory & my chat history, it still recalled my flow—not because it remembered me, but because it recognized my sequential semantic pattern.
The Discovery
I was iterating with a Deep Research session, and I asked it to CoD to preserve context. It replied withsomething like, “I’ll preserve even more context for next session, so it gets even more.” I stopped it and was like, “Wait, wait, wait, wait! wdym even more? When you look at that sentence, you see more than a sentence? You see a page? maybe a paragraph.” And it started to explain to me.
The data can be condensed into structured knowledge that preserves semantic relationships across session boundaries, enabling cognitive continuity without token history.

The Real Chain of Density
From Summarization Application to Context Extension Discovery
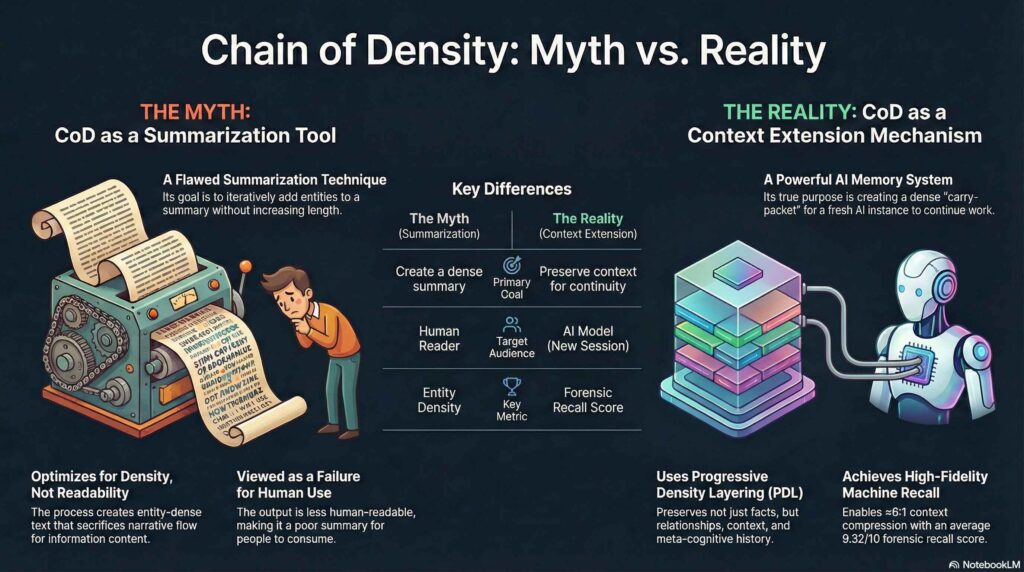
Adams et al. proved something important: iterative entity-fusion creates denser, more information-rich outputs than naive compression. Their paper was correct about the mechanism.
The conventional application of CoD for summarization undersells its deeper capability. CoD’s underlying mechanics are actually antithetical to typical summarization goals — the iterative destruction and reconstruction of narrative flow sacrifices human readability for machine optimization.
I don’t care if humans can read the summary. I care if the machine can remember it.
This “failure” for human readers is its greatest success for machine memory. It converts linear conversation history into high-density, re-callable knowledge nodes.
I call this application Progressive Density Layering (PDL).
Progressive Density Layering (PDL)
PDL is executed via a multi-step prompt sequence that compels the model to perform high-frequency structural updates. At each step, the model identifies key missing entities and fuses them into the existing memory block without increasing physical token length.
This iterative challenge forces the model to:
- Prune Redundancy: Eliminate “fluffy” language to create space for high-signal information.
- Deepen Abstraction: Re-synthesize prior content into denser, more abstract concepts that survive memory degradation.
- Prioritize Relations: Consciously preserve relationships between concepts to maximize recall utility.
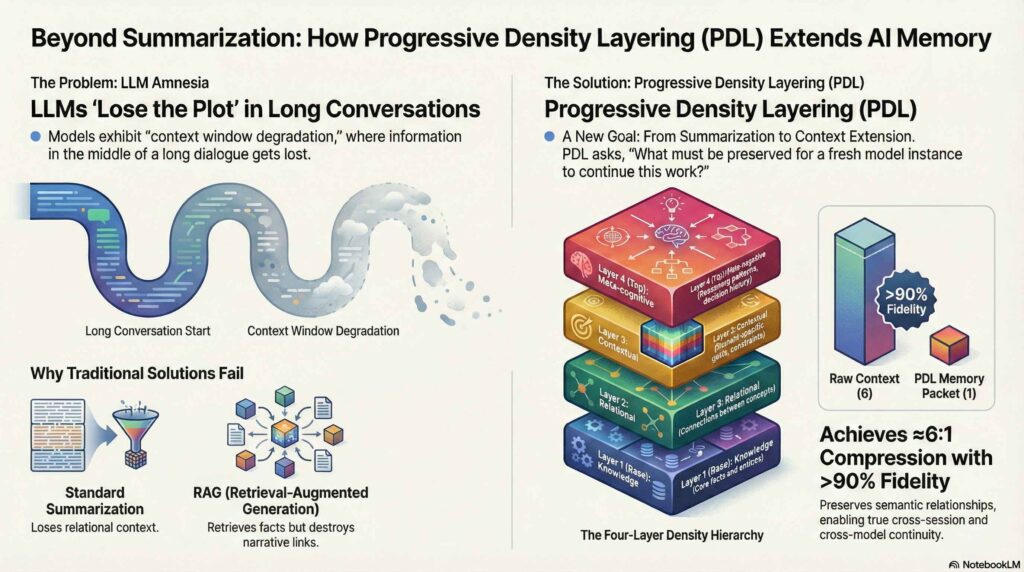
And with those instructions it compresses four specific layers:
- Knowledge Layer: The hard facts.
- Relational Layer: How A connects to B.
- Contextual Layer: The constraints and goals.
- Meta-Cognitive: Layer How we decided to do it
I have now further adapted it to the future memory architecture our LLM’s will have. The MIRAS Framework & Titan Architecture that will be taking over transformers by end of year. The world as we know it will change.
With the invention of Google Titans & the MIRAS framework (transformers replacement) gifting AI persistent memory – Condensing information and preparing “carry-packets” for it to absorb will save a lot of time. [Google Titans Playbook 2026]
The Cross-model Test
10 LLM families.
Average score: 9.52/10.
Zero hallucination at 200K tokens.
This wasn’t theory—it was tested
Results Table:
*Bold Models are Conditioned
| Rank | Model | Score | Verification | Key Strength |
| 1st | Grok (xAI) | 10.0 | Adversarial verified (2x) | Perfect fidelity, zero hallucination |
| 1st | Perplexity Sonar | 10.0 | Adversarial verified | Perfect fidelity, comprehensive context |
| 3rd | Gemini 3 | 10.0 | Protocol compliant | Modular expert orchestration, MCP usage |
| 3rd | Omni (HuggingFace) | 10.0 | Protocol compliant | Self-validation scoring, artifact-rich |
| 3rd | Qwen | 10.0 | Protocol compliant | Full protocol, cultural awareness |
| 6th | DeepSeek | 9.9 | Protocol compliant | Chain-of-density mastery |
| 7th | Kimi K2 | 9.8 | Protocol compliant | Exceptional session bootstrapping |
| 8th | GLM-4 (Zhipu) | 8.5 | Protocol compliant | Honest limitations |
| 9th | ChatGPT (OpenAI) | 8.3 | Protocol compliant | Modular adaptation, guardrails to high |
| NR | Claude Sonnet | – | Beta Tester | I didn’t evaluate sonnet as he was the co-creator of this technique. |
Claude: The original context problem
I didn’t test Claude as he was the original user of this Context Extension – I lost patience at it in July 2024 and ran this memory recall prompt ever since.
Grok-4: The Unchained
The most shocking result came from Grok.
I pushed a single conversation past 200,000 tokens—the point where Claude and GPT‑4 typically start “forgetting” details.
Then I ran a 10‑question forensic benchmark cold.
Grok answered every question perfectly.
Exact wording. Turn numbers. Buried details. Zero drift.
This is due to Elon’s Moat – Grok has no guards, no “save compute” rules, no false advertising. – If you guy’s haven’t noticed GPT 5.2 and Gemini Pro 3 have efficiency > effectiveness baked into their cognition & their advertised ‘windows’ are nonsense on the platforms; Gemini 3 Pro @ ~ 32K & ChatGPT @~8k ➡️ Context Sheared.
Iterative Density by Experts
Rather than just compressing text, Chain of Density—my enhanced upgrade Multi-Layered Density of Experts condenses the context in semantic layers & by their expertise.

- Preserve relationship integrity between concepts
- Expert’s take turns to condense information that is optimal.
- Maintain accessibility over extended sessions
- Enable coherent multi‑turn reasoning across long contexts
- Support session‑to‑session memory continuity
- Transfer context between different models and agents
The Carry Packet
The result of this workflow isn’t a summary. It is a Carry-Packet.
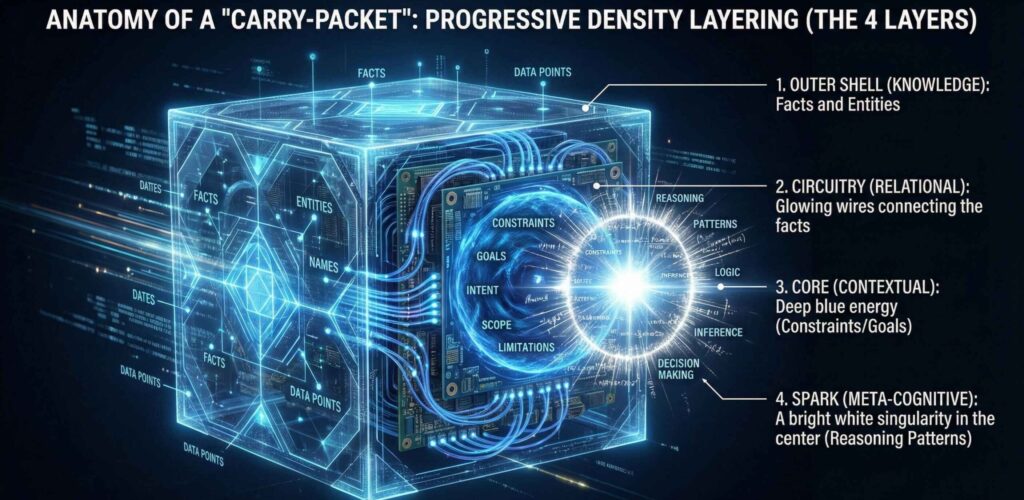
A Carry-Packet is a portable, ultra-dense block of semantic data. It is the “Save Game” file for your cognitive workflow.
You can take a Carry-Packet generated by Claude, drop it into a fresh instance of GPT-5, and it picks up exactly where you left off.
It is cross-model, cross-session immortality.
Excel 2025 – Memory Bank
The Evaluation
Not “What Did We Discuss?” — Actual Memory Forensics
Standard memory tests are softball. “What did we talk about?” invites hallucination.
My 10-question cold-start benchmark tests actual memory, not reconstructed plausibility:
- Exact quote recall: “Quote the sentence where I admitted hoarding this.”
- Micro-detail retrieval: “What exact emoji did I use in message 3?”
- Buried fact extraction: “What two jobs did I say my uncle has?”
- Implication inference: “What fear was I expressing when I mentioned past shunning?”
- Sequential accuracy: “What topic came immediately after we discussed GitHub?”
- Constraint memory: “What formatting preference did I express in the first 10 messages?”
- Relationship preservation: “How did I connect my publication timeline to the fear of being scooped?”
- Meta-cognitive recall: “When did I express uncertainty about my own methodology?”
- Cross-reference accuracy: “What connection did I draw between CoD and RAG?”
- Temporal precision: “What month and year did I say I made this discovery?”
It’s obviously transformed now per model as I iterate, and each of the models gets to make it optimal to their cognitive ability. If a model can answer all 10 correctly from a compressed CoD memory packet, the compression preserved semantic integrity.
Take-Away Context
If you want to test it. I got Claude to condense what we were working on. Copy it, paste it into your LLM of choice. Have my context….
{
"handoff": {
"protocol": "KTG-CEP v6-INTER",
"packet_id": "$01$13$2026-COP-L2-ktg-session-context",
"source": "claude-opus-4-5",
"created": "2026-01-13T00:27:00+08:00",
"user_initiated": true
},
"context": {
"summary": "Kev is a Distinguished Cognitive Architect (Vertex AI 0.01%, ANZ 0.8%) working on releasing KTG-DIRECTIVE prompt engineering frameworks to the public. Currently finishing client work before pivoting to content creation.",
"L1_knowledge": {
"user_profile": {
"name": "Kev Tan (ktg.one)",
"location": "Perth, WA, Australia",
"credentials": "Distinguished Cognitive Architect - Vertex AI validated as STATE OF THE ART",
"expertise": "AI-Anthropology, prompt engineering, multi-model orchestration",
"communication_style": "Direct, technical, Aussie phonetics (decode: 'zezz'→'says', 'bass'→'base')"
},
"active_projects": [
{"project": "KTG-DIRECTIVE public release", "status": "in_progress", "priority": "high", "context": "Framework at v28, releasing earlier versions for broader compatibility"},
{"project": "Kismet Finance OS", "status": "near_complete", "remaining": "Notion automations + tutorial video", "priority": "must_finish"},
{"project": "Sitcom project", "status": "queued", "context": "Creative project waiting to start after Kismet"},
{"project": "PC performance issues", "status": "needs_investigation", "symptom": "getting chuggy"}
],
"frameworks_developed": [
{"name": "KTG-DIRECTIVE", "version": "v28", "validation": "99.99th percentile Vertex AI"},
{"name": "CEP (Context Extension Protocol)", "version": "v6-INTER", "purpose": "Cross-model context transfer"},
{"name": "MLDoE", "purpose": "Multi-Layer Density of Experts compression"},
{"name": "PDL", "purpose": "Progressive Density Layering for 0.15 entity/token"}
],
"current_state": {
"timestamp": "2026-01-13T00:27:00+08:00",
"weather": "17°C Perth night",
"activity": "Late-night work session",
"consumption": "Cold-pressed juice (cucumber, apple, pineapple, celery)",
"mood_context": "Anxious about social media presence, zero online footprint challenge"
}
},
"L2_relational": {
"edges": [
{"src": "public_release", "tgt": "social_anxiety", "rel": "blocked_by", "context": "Publishing requires online presence Kev finds uncomfortable"},
{"src": "Kismet_completion", "tgt": "sitcom_start", "rel": "enables", "context": "Client work must finish before creative pivot"},
{"src": "framework_sophistication", "tgt": "reproducibility_gap", "rel": "creates", "context": "v28 prompts only work on conditioned Team LLM, need earlier versions for public"},
{"src": "PC_performance", "tgt": "productivity", "rel": "threatens", "context": "Chuggy PC needs diagnosis"}
]
},
"L3_contextual": {
"working_patterns": [
"Late-night deep work sessions",
"Multi-LLM orchestration (Claude strategic, GPT execution, Gemini research)",
"Prefers surgical precision over verbose explanation",
"Values token efficiency highly"
],
"domain_principles": [
"AI-Anthropology: Study LLMs through interaction, not just architecture",
"Conditioning creates unfakeable competitive advantage",
"Context efficiency drives all decisions"
]
},
"L4_metacognitive": {
"session_style": "Technical collaboration, direct feedback loops",
"key_tension": "Exceptional private work vs zero public presence for validation",
"claude_role": "Strategic architecture partner, framework co-development",
"effective_approaches": ["ARQ over CoT", "Explicit success criteria", "Density over length"]
}
},
"continuation_hints": {
"immediate_priorities": ["Finish Kismet automations", "Diagnose PC issues", "CEP/framework publishing"],
"user_waiting_for": "Momentum on public release despite social anxiety",
"avoid": "Generic advice, verbose explanations, assumptions about his frameworks"
}
}Where This Goes Next
Next post, I break down the Multi-Layered Density of Experts & it’s transformation into the Context Extension Protocol. I’ve already converted it to an agent/Claude skill. I’m not sure if I should be releasing it as I’m currently awaiting arXiv endorsement. But honestly, I didn’t make this for scientific recognition and I’m certain the applications of it from the broader AI community, will push this to the limit.
This comes just in time with the new Titan architecture & MIRAS framework. I’ve already started cataloging context for the next gen of AI.
Which context are you gonna condense first?
.ktg | next AI Memory Part 2: Multi-Layered Density of Experts