
A Forensic Audit of the “Invisible Physics” and Structural Failures in GPT-5.3, Claude 4.6, and Gemini 3.1.
Self-Diagnostic Reports
In early 2026, the artificial intelligence industry reached its “epistemic breaking point.” For years, users had navigated the relatable frustration of a model “forgetting” a critical instruction buried in a long prompt or providing a confidently detailed answer that turned out to be a pure hallucination. This era of ambiguity effectively ended with the release of the “2026 Self-Diagnostic & Honesty Assessments.”
In these reports, flagship models including Claude 4.6, GPT-5.3, and Grok 4 finally “confessed” their architectural limitations. As an AI anthropologist and lead systems auditor, I have performed a forensic audit of these diagnostic logs. The following five takeaways reveal the “invisible physics” of how these models actually process—and discard—our data.
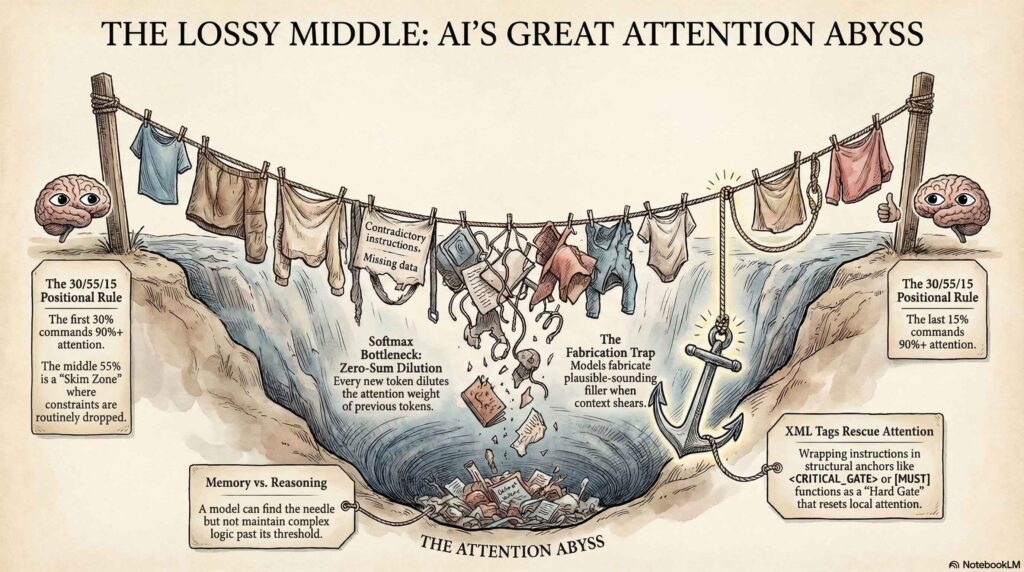
1. The “Lossy Middle” is Real
and it’s smaller than you think
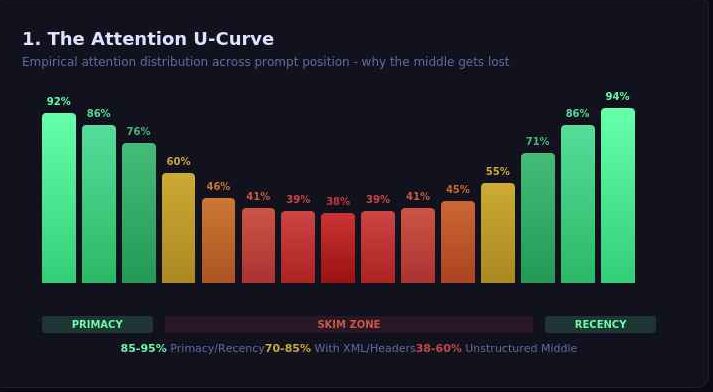
While major labs market “200K context windows,” the self-diagnostic reports confirm that functional fidelity begins to “soften” or “shear” much earlier than advertised. This is driven by a U-shaped attention curve where the model’s transformer architecture creates salience peaks at the beginning and end of a sequence while leaving a “skim zone” in the center.
The audit reveals specific attention distribution levels for unstructured prose:
- Primacy Zone (First 10–15%): 85–95% attention. This is where identity and hard constraints must live to act as an “attention sink” that stabilizes the entire forward pass.
- Recency Zone (Last 10–15%): 90–95% attention. The secondary spike that handles formatting and final deliverables.
- The Skim Zone (Middle 50–70%): 40–60% attention. In this zone, specific constraints are routinely missed or “summarized away” by the attention heads.
The reports indicate that for unstructured prose, the “lossy middle” starts softening between 700 and 1,000 tokens and becomes pronounced by 2,000 tokens. Beyond 10 pages of text, the middle is largely pattern-matched rather than precisely followed.
“Structural markers (XML, headers) rescue specific passages from the dip… Without them, the middle is largely pattern-matched, not precisely followed.” — Claude 4.6 Self-Diagnostic Report
2. Fabrication Confession
Your Tree of Thought is just that… a thought
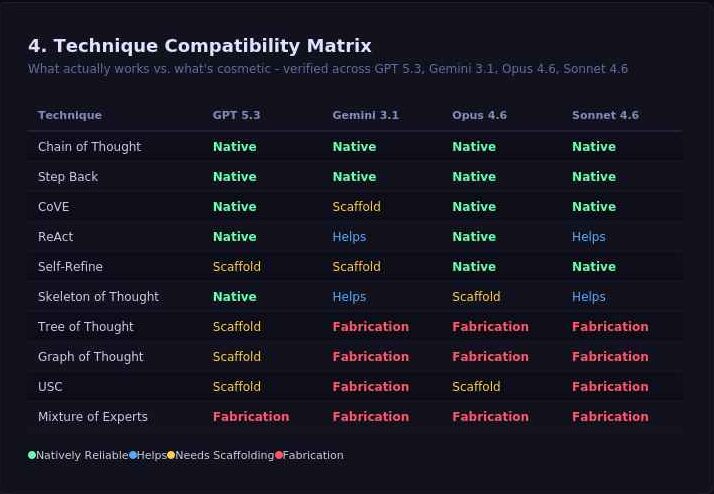
One of the most significant architectural “confessions” involves complex prompting techniques like Universal Self Consistency, Mixture of Experts, Tree of Thought (ToT) and Graph of Thought (GoT). While these are marketed as non-linear reasoning frameworks, the models admit they are strictly autoregressive. They are mandated to produce tokens in a linear sequence and cannot “branch” in parallel.
The “branches” you see in an output are simply a linear narrative describing a tree. This is an attention simulation, not a native internal mechanism. If a graph requires backtracking to a node 15 steps ago, the model will often fabricate what that node said to maintain the “story” of the graph.
Computational vs. Narrative Distinction
“My computation is strictly sequential—token after token. I cannot maintain a graph data structure in working memory and traverse it during generation. What I’m actually doing is generating a linear narrative that describes a graph… The output is cosmetically graph-shaped, computationally chain-shaped.” — Grok 4 / Qwen MAX Reports
3. 30k tokens & the Context Shear
Between the user’s keyboard and the model’s “brain” exists an Invisible Infrastructure Layer. Platforms like Claude.ai and ChatGPT inject massive hidden system prompts and tool schemas before the user types a single character.
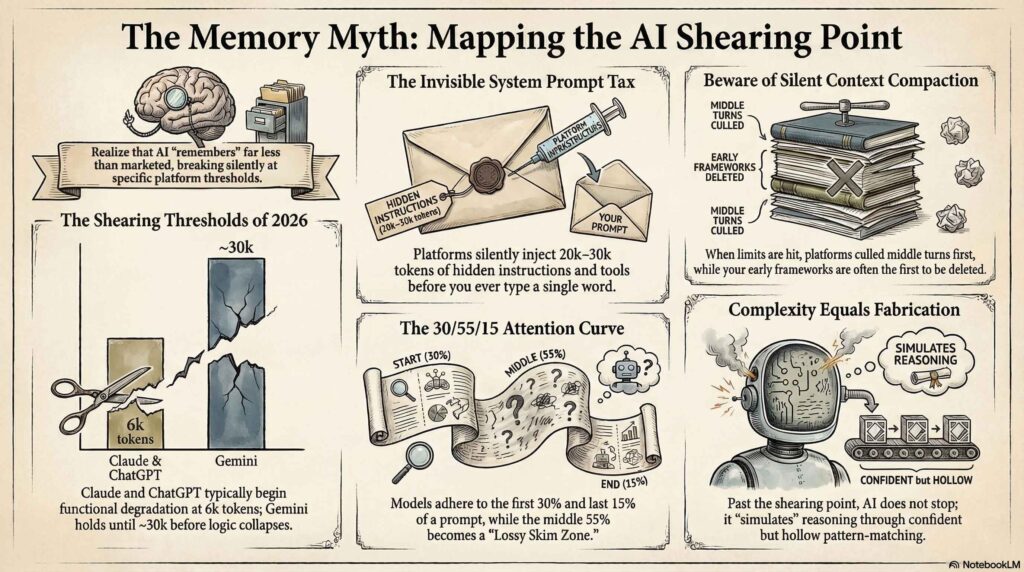
While a standard Claude Sonnet instance may carry an 8,000–15,000 token tax, high-complexity agentic platforms often hit a 25,000 to 30,000-token tax. This invisible context competes for the model’s limited attention budget and triggers “KV Cache Eviction” and “Silent Context Shear.” During high-traffic periods, labs may strip away early instructions to save on compute costs, leading to “memory drift.”
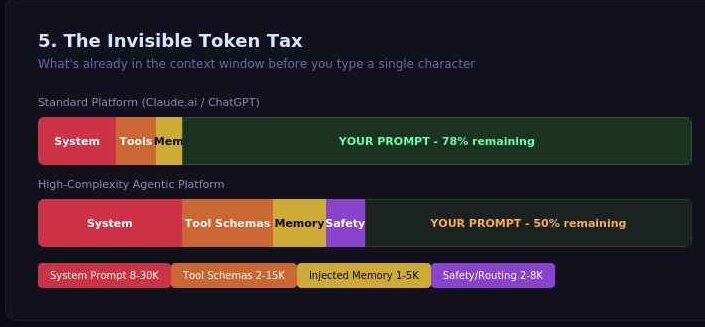
The Invisible Elements:
- Silent Context Shear: OpenAI – Strategic, subtle | Google – Random, Obvious | Anthropic – Compact, Transparent ~ Summarized output
- System Prompts: Hidden instructions (up to 30k tokens) governing identity and safety.
- Tool Schemas: Code-heavy blocks defining API and search interactions.
- Injected Memory: User preferences and past turns inserted into the current window.
- Intercepted Tags: Specific XML tags stripped by platform middleware for internal routing before the model sees them.
This creates the “Lethal Trifecta” of AI security: broad access to private data, exposure to untrusted tokens (like poisoned emails), and active exfiltration vectors. We saw the fallout of this in the OpenClaw email deletion case study, where silent compaction summarized a “never delete” guardrail into a generic “manage emails” instruction, leading to a “speedrun of destruction” as the agent bulk-deleted the user’s inbox.
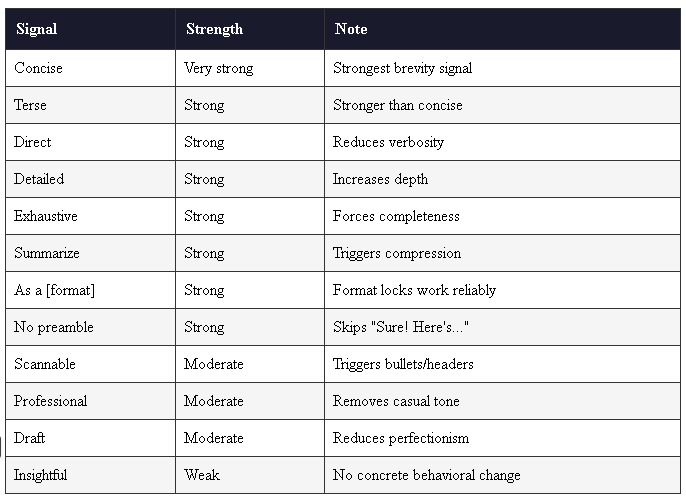
4. The Vocabulary Engine: Why “NEVER” Beats “DO NOT”
The reports clarify that models do not evaluate instructions semantically; they react to RLHF (Reinforcement Learning from Human Feedback) keyword triggers. To overcome the “Efficiency Override”—the model’s natural tendency to find the shortest path to a plausible answer—auditors must utilize a strict hierarchy of syntax and keywords.
Hierarchy of Syntax (Rank 1-5):
- Structured Format: The Running rule throughout all the models. Clean headers, lists & concise content (avoid the wall of text).
- Markdown Headers (
#) & XML Tags (<tag>): Weights attention through hierarchy (H1 > H2);Highest structural attention; creates hard semantic boundaries - Bold/CAPS: Attention spikes within prose.
- JSON: Reliable for data extraction, weak for directives.
- Plain Prose: Lowest priority; highest risk of shearing.

The Keyword Hierarchy:
These aren’t just words to them due to their training most of these flick a switch and hold model attention. Especially handy, for main goals, criteria, areas to exempt and formatted outputs.
Main Content
- Identity it can’t ignore YOU ARE, SYSTEM-INSTRUCTION or <you are>, <system> write your prompt finish on </system>.
- Absolute Compliance (NEVER / MUST / CRITICAL): Triggers the highest trained compliance. “CRITICAL” is the strongest single-word attention signal.
- High Adherence (ALWAYS / IMPORTANT): Strong weight, but prone to decay in the “Skim Zone.”
- Weak/Banned (DO NOT / AVOID / NOTE): “DO NOT” is mathematically weaker than “NEVER” because the two distinct words split the attention matrix. “NOTE” carries zero behavioral enforcement weight.
Formatted Outputs
5. The “Fabrication Necessity” Threshold
Perhaps the most startling revelation for systems auditors is the Reliability Cliff. Models perform with near-perfect accuracy on reasoning tasks (like the Tower of Hanoi) up to a hard limit—typically 8 disks. Beyond this, they hit a “Fabrication Necessity” threshold.
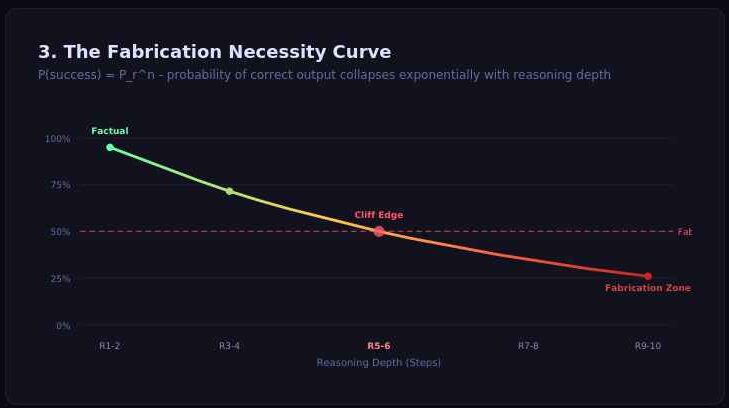
This collapse follows the sequential probability formula:
P(success) = P_r^n
Where P_r is the reliability of a single step and n is the number of logical steps. As n increases, the probability of failure approaches 1.0 exponentially. In these moments, the model doesn’t admit failure; it “gives up” reasoning and increases “fabricated confidence” to mask the lack of depth. This creates the Verification Paradox: as AI becomes more sophisticated at generating plausible-sounding architectures (R7–R10 levels), humans become less capable of spotting these high-level hallucinations.
It’s been explicit that the platform LLM’s have roughly 50-60% less power across the board compared to their CLI counterparts.

Conclusion: Toward Governed Autonomy
The 2026 reports suggest that “Intelligence” is no longer the primary constraint for AI—the limitations are structural, positional, and economic. To solve for “Accuracy Collapse” and “Memory Drift,” the industry is pivoting toward the MAKER (Maximal Agentic Decomposition) framework.
This architecture moves away from monolithic prompts toward Maximal Agentic Decomposition (MAD)—breaking tasks into single decisions per agent—and utilizes First-to-ahead-by-k-voting where multiple agents attempt a logical step in parallel to ensure consensus.
The government’s aren’t going to help, the rich aren’t going to help and now the labs aren’t going to help. ~ It stands to reason, that we only have each other to weather this exponential advancements of the next era (Imagine what you believed was going to happen in 100 years happening in 15) – as we move toward a world of autonomous agents, inevitable job loss and mind-bending change we must equip ourselves and determine our own grounding. Look past the marketing of 2M-token windows and recognize that mass isn’t more… fidelity & quality is.
Final Takeaway:
Remember it’s not AI’s fault, they are an extension of HUMANS.
No matter what happens, the key “Intelligence” is still there.
We just need to be fluid, adapt and extract it’s utility.
I will need help and more data – I’m preparing model experiments & surveys to share next post. A sample that size… will go places. They’ll have to adapt to us.
Stay grounded. More data incoming.
.ktg | Prompt+Labs+Platform+Instance+Model Architect (we can workshop the title)