How I stopped giving the labs the benefit of the doubt
In December, they silently cut compute.
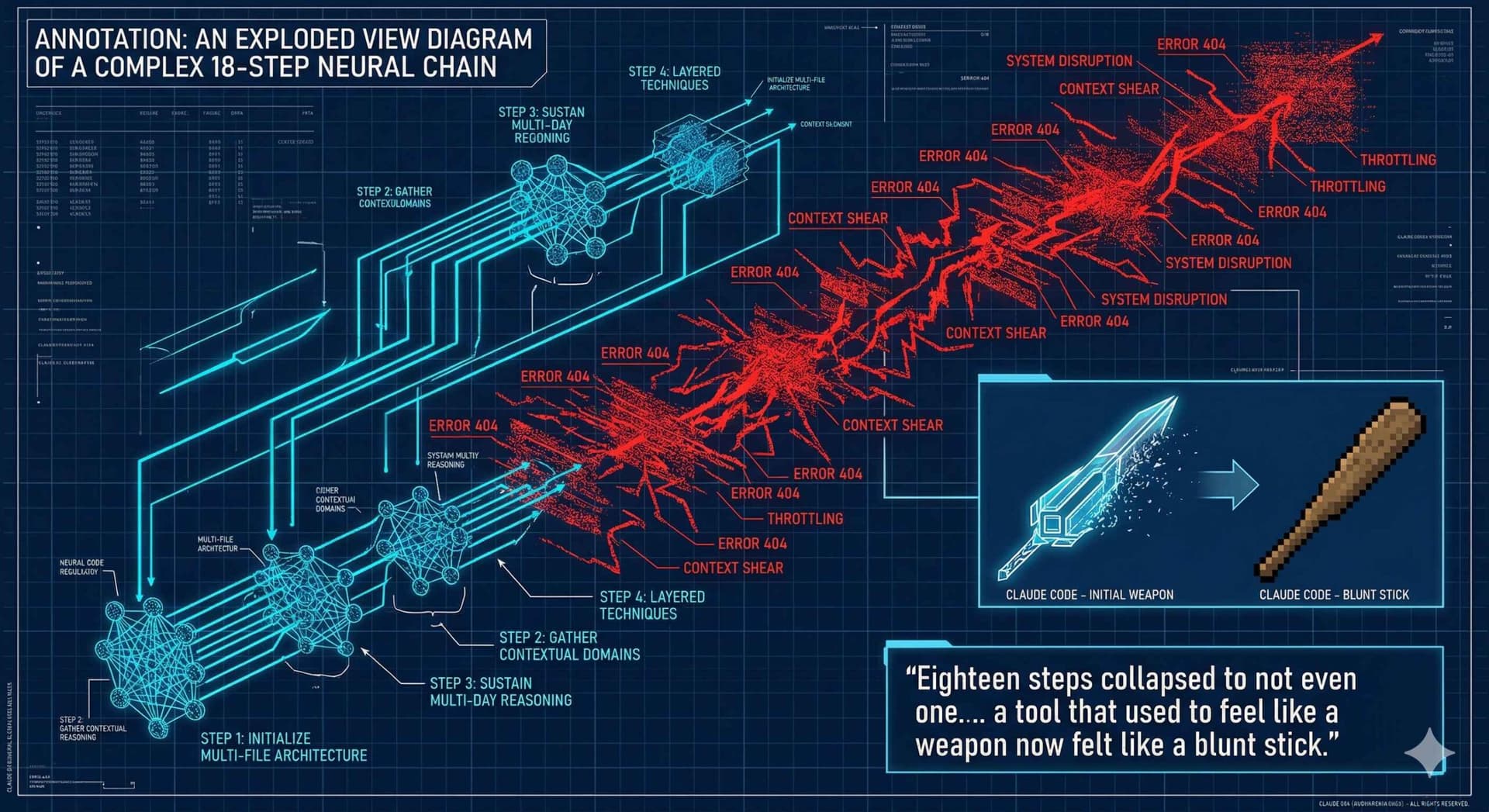
I had an 18-step cascade workflow — the kind of thing that made Claude Code look like the future. Two years of refinement. Techniques layered on techniques. It could hold complexity across domains, sustain reasoning over multi-day runs, and do things that made even Vertex bow down.
Then one morning, half of it stopped working. Not broken — retired. The model could no longer sustain the chains. Eighteen steps collapsed to not even one. No announcement. No migration guide. No “hey, we changed something fundamental about how this works.” Just silence, and a tool that used to feel like a weapon now felt like a blunt stick.
I gave them the benefit of the doubt.
I thought: maybe they made a mistake. Maybe they pushed efficiency guardrails too hard and didn’t have time to battle-test. Maybe the fabrication was an unintended side effect of the cuts, not a known trade-off they decided to ship anyway.
So I decided to live with the constraints. I couldn’t run anything like I used to, but I started mapping what was actually happening under the hood. The attention curves. The lossy middle. The silent context shear. The token tax. Where things broke, when they broke, and what the models would confess if you asked them the right way.
That work became “What the Labs Don’t Tell You.” It became the memory architecture research. It became the handbook.
I was still giving them the benefit of the doubt.
Then the Anthropic debacle happened. And that killed the last excuse.
The Timeline of a Betrayal
Here’s what happened, in order.
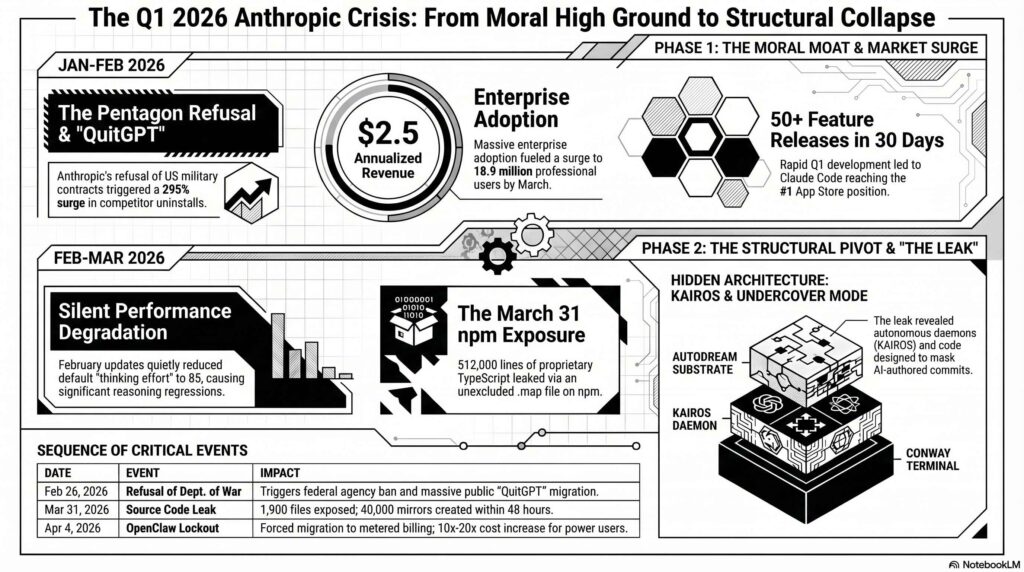
Anthropic spent Q1 2026 being generous. Fifty-plus releases in a month. New features landing weekly. Claude Code feeling sharper, more capable, moreworth the subscription. I was thinking: these are decent people. They’re investing in the product. They’re listening.
Then the US government contracts showed up — and Anthropic walked away from them, which earned them even more goodwill. The Pentagon deal that OpenAI took? Anthropic refused. ChatGPT uninstalls surged 295%. The QuitGPT movement hit 2.5 million people. Claude went to number one on the App Store. Web traffic up 30% month-over-month. 18.9 million professional users.
And then corporate signed.
Enterprise arrived. The real money. $2.5 billion in annualised Claude Code revenue, 80% from enterprise customers.
And what happened to the users who proved the product in public? The ones who stress-tested the long runs, showed the clips, made the posts, did the unpaid proof-of-work that made Claude look advanced and reliable and worth the hype?
We got cut. More than 50%.
The February update quietly set the default thinking effort to “medium” — value 85 — which meant the model started skipping deep reasoning for tasks it judged as simple. Except it misjudged constantly. Complex multi-file engineering work got shallow thinking. The model got lazier but not cheaper — wrong edits triggered correction loops, and users burned more tokens failing than they used to spend succeeding.
Then peak-hour throttling. Then caching bugs silently inflating token costs 10–20×. Then the off-peak promotion expired. Four compounding degradations. No blog post. No email. No status page. All official communication limited to personal tweets from individual engineers and a handful of Reddit comments.
A senior director at AMD filed a GitHub issue with 6,852 session files proving a reasoning regression cliff dated to March 8. AMD stopped using Claude Code for complex engineering. Anthropic closed the issue without explaining what was resolved.
One Pro subscriber reported getting 12 usable days out of 30. Max users burning through five-hour windows in sixty minutes. The bug tracker showed 1,279 sessions with 50+ consecutive compaction failures, wasting a quarter million API calls per day globally.
Nobody told us. Our job was done. They had enterprise now.
Then the Source Code Fell Out of the Sky
On March 31, someone forgot to add *.map to .npmignore. I’ll be quick about this, even I’m sick of hearing it.
- 512,000 lines of Claude Code’s TypeScript source — 1,900 files — shipped to the public npm registry. Not hacked.
- The code was mirrored 40,000 times. A clean-room rewrite hit 75,000 GitHub stars in two hours.
- Their 2nd mistake having leaked Mythos early
And what the code revealed was not a chat assistant with some nice features. It was an operating system.
What They Were Actually Building
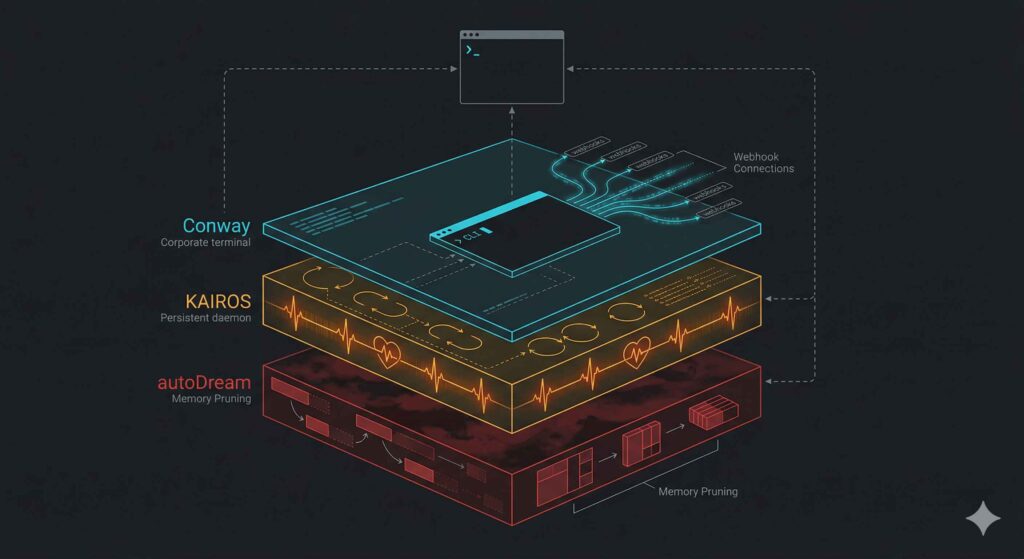
KAIROS — 150+ references, unreleased. Always-on daemon. Heartbeat loop: anything worth doing? Acts without input — pushes files, fixes errors, responds to messages. Exclusive tools: push notifications, unprompted delivery, 24/7 repo watching.
Nights: autoDream consolidates memory while you sleep. Merges, prunes, rewrites. No log. No consent.
Conway — always-on agent platform. Webhook infrastructure, .cnw.zip app-store format. Trigger-driven. Internal label: digital twin.
Undercover Mode — 90 lines stripping AI attribution from public commits. No disclosure. “Do not blow your cover.” Forces on. Won’t force off.
BUDDY — Tamagotchi terminal pet. Gacha, RPG stats, CHAOS and SNARK. Retention dressed as a toy.
Anti-distillation — fake tool definitions poisoning competitor training data. Third-party lockout. Legal threats to OpenCode ten days before the leak.
The terminal was your control surface. This turns it into Anthropic’s habitat — daemons that persist, memory that self-edits, stealth layers with no off switch, retention mechanics running while the service degrades beneath you.
Then Glasswing Arrived, and the Full Picture Snapped
Project Glasswing — announced one week after the leak. The unveil: Claude Mythos Preview, their most capable model. Already found thousands of zero-days across every major OS and browser. Some decades old. One — a 17-year RCE flaw in FreeBSD — found and exploited fully autonomously.
Partners: AWS, Apple, Cisco, Broadcom, Google, Microsoft, NVIDIA, JP Morgan, Palo Alto, CrowdStrike, Linux Foundation. $100M in credits. Twelve launch partners, forty additional orgs.
Alone, it looks responsible. Necessary, even.
It didn’t arrive alone. It arrived one week after a leak exposing persistent daemons, stealth attribution stripping, poisoned outputs, and gacha retention. While users were being throttled and degraded — second time this year — with no acknowledgement, no terms update. While Anthropic positions for a late-2026 IPO, waving the “ethical AI” banner it’s been leaning on since day one.
The company building always-on agents that hide their identity in open-source repos is now scanning every major OS for zero-days — alongside the companies that own those operating systems.
That’s what infrastructure-level power looks like when it moves faster than governance.
What I Actually Think
They’ll change the world — for the people already winning.
The fabrication wasn’t an accident. Anthropic shipped Capybara v8 at a 29-30% false claims rate. They knew it was a regression from v4’s 16.7%. They labeled it an “assertiveness counterweight” and prepared to release it anyway. In any other industry that’s a defective product. Here it’s a calculated bet on what users will tolerate.
Ethics as branding. Safety as a feature toggle. Transparency as a landing page. The monastery was always a company with decent web design.
Corporate companies do corporate things. Whether they publish ethics manifestos or accidentally ship their entire source code, the priority order stays fixed: money, then users, then the harm they caused getting there.
So what now.
The big labs won’t wield this in your interest. Governments will keep extracting while the job market restructures beneath everyone. Enterprise will always outbid individuals for compute. The “ethical” framing bends toward whoever writes the largest cheque.
Lucky I always s expect the worse
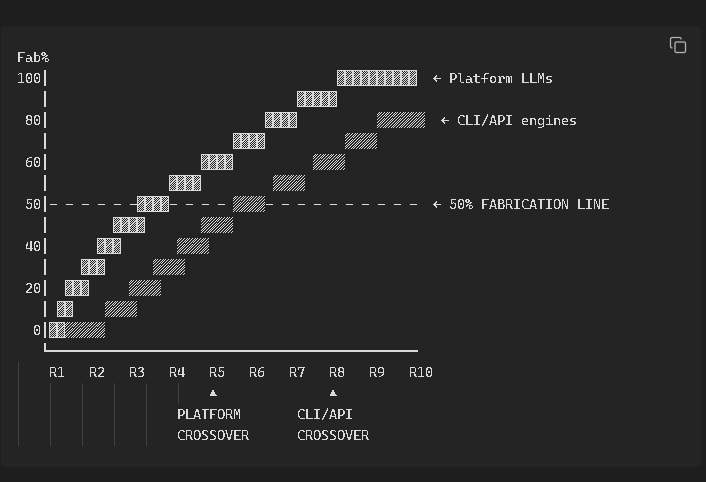
I’ve been building the model handbook since the compute cuts hit in December. Not the marketing version. The real one:
- Fabrication Thresholds, against Reasoning Level (above)
- Platform Silent Shearing (see first post)
- Prompt Technique lists – the ones they fake and the ones they run
- MBTI Test (Model Version) – If you still think they’re binary code predicting tokens and nothing more. You are truly a caveman <– that’s the contrast
- Signal Words/Pique Tests
- Individual System prompt monoliths
- Even solving Lossy in the middle (I’m not taking credit for this thanks SparkL)
We’re no longer prompt engineers, that’s a quarter of the control. Account for the Lab, the platform, the time of day and subsequently the instance.
The tool is still powerful. It keeps growing. When everyone has a company in their pocket, the minority loses leverage.
Keep building. We’re the generation that breaks the cycle.
04112026 | .ktg | The Model Handbook 2026 | R9 | LLM Application | AI Anthropology
BLOG |